Welcome the blog of the Computing Service of the UPV/EHU
Special Issue “Large Eddy Simulation and Turbulence Modeling”
September 5th, 2019
Journal of Marine Science and Engineering Special Issue in “Large Eddy Simulation and Turbulence Modeling”
Dear Colleagues,
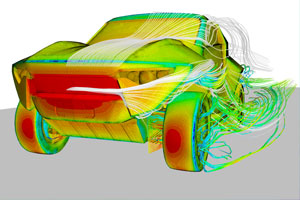
![]() Computational power has been improved over last decades; therefore, complex flow modeling phenomena using computational fluid dynamics (CFD) has become more feasible. Furthermore, the improvement of computational power is expected to continue and will serve to progress in the CFD modeling capabilities.
Computational power has been improved over last decades; therefore, complex flow modeling phenomena using computational fluid dynamics (CFD) has become more feasible. Furthermore, the improvement of computational power is expected to continue and will serve to progress in the CFD modeling capabilities.
The role of turbulence is essential to the understanding, prediction and improvement of complex flows. In fact, turbulence is vital to the proper operation of many industrial applications. LES is typically computationally less expensive than Direct Numerical Simulations (DNS) and, of course, computationally more expensive than Reynolds Averaged Navier-Stokes (RANS) models. However, thanks to the current advances in computational power, large grids and therefore LES for complex engineering flows have become feasible and very useful.
The purpose of the current Special Issue is to publish the most exciting research with respect to the above subjects and to spread the articles freely for research, teaching, and reference purposes.
Dr. Unai Fernandez-Gamiz
Guest Editor
Deadline for manuscript submissions
26 March 2020
Keywords
Aerodynamics, Hydrodynamics, Flow Control, Vortex Modeling, Large Eddy Simulation (LES), Turbulence Modeling, Computational Fluid Dynamics (CFD), Heat Transfer, Cooling Systems, Complex Flows, Coherent Structures.
Author Benefits
- Open Access: free for readers, with article processing charges (APC) paid by authors or their institutions.
- High visibility: Indexed in the Science Citation Index Expanded in Web of Science, in Inspec (IET) and in Scopus.
CiteScore (2018 Scopus data): 1.76, which equals rank 30/92 in ‘Ocean Engineering’, rank 105/288 in ‘Civil and Structural Engineering’ and rank 77/203 in ‘Water Science and Technology’.
More information
https://www.mdpi.com/journal/jmse/special_issues/large_eddy_simulation
Guest Editor

Dr. Unai Fernandez-Gamiz
Afiliation
University of the Basque Country | UPV/EHU
Nuclear Enginnering and Fluids Mechanic
Spain
Email
unai.fernandez@ehu.eus
Web
https://scholar.google.com/citations?user=M297EIkAAAAJ&hl=en&oi=sra
Phone
+34 945014066
Interests
Fluid Mechanics; Modeling and Simulation; Computational Fluid Dynamics, Flow control, Aerodynamics, Offshore Renewable Energy (ORE) such as off-shore wind turbines or wave energy converters (WEC), Oscillating Water Column (OWC) devices, hydrodynamics and dynamics of floating bodies under the presence of ocean waves; optimization of passive flow control systems(e.g. vortex generators, moving flaps, Gurney flaps or microtabs), Heat transfer, Internal combustion, Cooling Systems, Complex Geometries, Turbomachinery Flows.
Licencias de software Siemens PLM
March 4th, 2019
El Servicio General de Informática Aplicada a la Investigación (Cálculo Científico) ha renovado la licencia corporativa para la UPV/EHU para el 2019 de varios programas de software de elementos finitos
Estas licencias pueden usarse en los clusters de cálculo del Servicio de Cálculo Científico de la UPV/EHU. También pueden solicitarse licencias personales para uso en los ordenadores de los investigadores, para ello es necesario realizar una solicitud a los técnicos del Servicio de Cálculo Científico.
Características de la licencia
La licencia será válida hasta Febrero del 2019 y permite el uso de todos los procesadores del ordenador. Se puede usar en ordenadores corporativos de la UPV/EHU o a través de VPN.
Se dispone de licencia de docencia que permite la instalación en las aulas de docencia de la UPV/EHU para impartir cursos y asignaturas.
Listado de paquetes software
Otros paquetes de Siemens PML consultar.
Tarifas
El uso del software en aulas y equipo del profesoraso para docencia de cursos y asignaturas es gratuito.
El uso del software en el cluster de cálculo Arina de la UPV/EHU es gratuito y solo se factura el uso de horas de cálculo según la tarifa estándar del Servicio.
Las tarifas que se aplicarán para la instalación de licencias en los ordenadores personales de los investigadores se detalla a continuación.
- Licencias de docencia y pruebas.
Para un PC. Se pueden solicitar licencias gratuitas para probar el programa, realizar tareas relacionadas con la docencia o proyectos de fin de máster.
- Licencias de investigación en PCs
Las licencias destinadas a su instalación en ordenadores corporativos personales cuyo uso va a ser de investigación se facturará a 250 € por paquete de software y equipo.
- Licencias de investigación en estaciones de trabajo y servidores.
Las licencias de STAR-CCM+ o HEEDS destinadas a su instalación en estaciones de trabajo y servidores (procesadores xeon o similares) tendrá un coste de 50 € por core por paquete de software.
Más información
- Para más información se puede poner en contacto con los técnicos del Servicio de Cálculo Científico.
- Página web de STAR-CCM+ en el Servicio de Cálculo Científico.
Agradecimiento
La Universidad del País Vasco quiere agradecer al programa educativo de Siemens PLM por las condiciones especiales de acceso al software.
Solicitud 2018 de licencias de STAR-CCM+ y HEEDS para investigación y docencia
February 5th, 2018
El Servicio General de Informática Aplicada a la Investigación (Cálculo Científico) ha renovado la licencia corporativa para la UPV/EHU para el 2018 del programa de dinámica de fluidos (CFD) STAR-CCM+ y el programa de HEEDS que automatiza el proceso de optimización de parámetros en diseños.
Estas licencias pueden usarse en los clusters de cálculo del Servicio de Cálculo Científico de la UPV/EHU. También pueden solicitarse licencias personales para uso en los ordenadores de los investigadores, para ello es necesario realizar una solicitud a los técnicos del Servicio de Cálculo Científico.
Características de la licencia
La licencia será válida hasta Febrero del 2019 y permite el uso de todos los procesadores del ordenador. Se puede usar en ordenadores corporativos de la UPV/EHU o a través de VPN.
Se dispone de licencia de docencia que permite la instalación de STAR-CCM+ en las aulas de docencia de la UPV/EHU para impartir cursos y asignaturas.
Tarifas de STAR-CCM+ o HEEDS
El uso de STAR-CCM+ en aulas para docencia de cursos y asignaturas es gratuito. El uso de HEEDS en docencia dependerá de la disponibilidad de licencias.
El uso de STAR-CCM+ y HEEDS en el cluster de cálculo Arina de la UPV/EHU es gratuito y solo se factura el uso de horas de cálculo según la tarifa estándar del Servicio.
Las tarifas que se aplicarán para la instalación de licencias en los ordenadores personales de los investigadores se detalla a continuación.
- Licencias de docencia y pruebas.
Para un PC y menos de 250 horas. Se pueden solicitar licencias gratuitas para probar el programa, realizar tareas relacionadas con la docencia o proyectos de fin de máster. Estas licencias estarán restringidas a un máximo de 250 horas de uso.
- Licencias de investigación en PCs
Las licencias de STAR-CCM+ o HEEDS destinadas a su instalación en ordenadores corporativos personales cuyo uso va a ser de más de 250 horas, y por tanto se consideran de investigación, se facturará a 250 € por equipo. Si se adquiere una licencia de STAR-CCM+ para el equipo la de HEEDS solo conllevará un suplemento de 50 €.
- Licencias de investigación en estaciones de trabajo y servidores.
Las licencias de STAR-CCM+ o HEEDS destinadas a su instalación en estaciones de trabajo y servidores (procesadores xeon o similares) tendrá un coste de 50 € por core. Si se adquiere una licencia de STAR-CCM+ para el equipo la de HEEDS solo conllevará un suplemento de 50 €.
 Más información
Más información
- Para más información se puede poner en contacto con los técnicos del Servicio de Cálculo Científico.
- Página web de STAR-CCM+ en el Servicio de Cálculo Científico.
- Página web de HEEDS
- Página web CD-Adapco, proveedor del software.
Memoria sobre el uso de STAR-CCM+ en 2017
January 25th, 2018
Con el objetivo de apoyar el área de Dinámica Computacional de Fluidos (CFD por sus siglas en inglés) por el alto valor añadido que aporta a la investigación y desarrollo de proyectos de ingeniería, la UPV/EHU a través del Servicio de Informática aplicada a la Investigación (Cálculo Científico), IZO-SGI, adquiere una licencia de STAR-CCM+ como software corporativo. Este software tiene una larga trayectoria en la UPV/EHU y presentamos la memoria de su uso en 2017.
Reparto del uso de STAR-CCM+
El uso de STAR-CCM+ tiene varias modalidades:
- Uso para investigación
- Uso en el cluster Arina de la UPV/EHU
- Uso en equipos propios del personal investigador
- Uso en docencia
- Clases
- Proyectos de fin de grado o master
La implantación en la docencia de este software como herramienta es cada vez mayor y se ha asentado en ciertas asignaturas y como herramienta en proyectos de grado y máster.
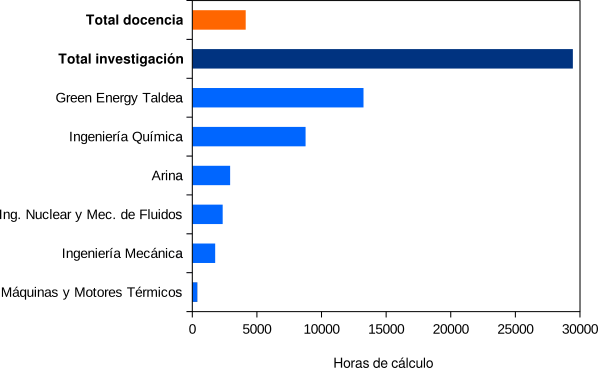
En 2017 se usaron un total de 33.582 horas de licencia de las cuales 4.133 fueron en docencia, un 12% del total, y 29.449 en investigación.
Las licencias de investigación se han desglosado por el uso en Arina y el uso en las máquinas personales de diferentes grupos o departamentos. Como mayores usuarios destacan el Green Energy Taldea y el departamento de Ingeniería Química. El uso en equipos personales ha sido de 26.521 horas que representa el 90 % del total de investigación y su uso en el IZO-SGI ha sido relativamente residual, sólamente del 10 % (2928 horas).
Memoria económica
El IZO-SGI gestiona por motivos de eficiencia la compra de software en general para su uso por cualquier investigador en el Servicio, pero no es tarea del Servicio la financiación de software corporativo. El gasto de software del Servicio está computado en la tarifa general del mismo dentro del uso de CPU.
La licencia de software permite su uso gratuito en docencia y se usa con este fin. Por la peculiaridad de este software es posible y necesaria su instalación en equipos personales de investigadores, es decir, el uso de la licencia se comparte entre los equipos personales y los del IZO-SGI. Por ello el Servicio también se apoya en el uso personal de los investigadores para repartir el costo de la licencia. El uso de la licencia en equipos personales de los investigadores representa el 90 % del tiempo y estos han aportado este año el 70 % de la financiación de la licencia. Por lo tanto, en 2017 se ha dado un equilibrio entre el uso y la financiación de la licencia.
Memoria científica
Publicaciones
1.- Parametric study of low-profile vortex generators
P. Martínez-Filgueira and U. Fernandez-Gamiz and E. Zulueta and I. Errasti and B. Fernandez-Gauna
International Journal of Hydrogen Energy,17700, 42, 2017
2.- Self-compacting concrete incorporating electric arc-furnace steelmaking slag as aggregate
A. Santamaría and A. Orbe and M.M. Losañez and M. Skaf and V. Ortega-Lopez and Javier J. González
Materials & Design,179,115,2017
3.- Computational Characterization of Aerosol Delivery for Preterm Infants.
I. Aramendia, U. Fernandez-Gamiz, A. Lopez-Arraiza, M. A. Gomez-Solaetxe, J. M. Lopez-Guede, J. Sancho, F. J. Basterretxea
International Journal of Biology and Biomedical Engineering, 28, 11 (2017)
4.- Computational Simulations of an Aerosol for Surfactant Delivery in Preterm Infants.
I. Aramendia, A. Lopez-Arraiza, M. A. Gomez Solaetxe, U. Fernandez-Gamiz, J. Sancho1, C.Rey-Santano, V. Mielgo and J. Lopez de Heredia
RICTA Barcelona 2017 (Póster)
5.- Aerosol Delivery by Inhalation Catheter and Trachea Digitalization
I. Aramendia, U. Fernandez-Gamiz, A. Lopez-Arraiza, M.A. Gomez-Solaetxe, L. Barrenetxea, E. Solaberrieta, R. Minguez , J. Sancho
XXXV Congreso Anual de la Sociedad Española de Ingenierı́a Biomédica. Bilbao, 29 Nov – 1 Dic, 2017
ISBN: 978-84-9082-797-0, 55-58
6.- Water droplets effects on an airfoil aerodynamic performance.
I. Aramendia, U. Fernandez-Gamiz, A. Lopez-Arraiza, M.A. Gomez-Solaetxe, J.M. Lopez-Guede and J. Sancho
International Journal Of Mechanics, 234, 11 (2017)
Proyectos docentes
- Simulación fluidodinámica y térmica de un precalentador tiop carcasa y tubos con sales fundidas. Asier Gutiérrez Uriarte. Escuela Técnica Superior de Ingeniería de Bilbao.
- Caracterización térmica mediante simulación de intercambiadores de calor y validación con datos experimentales. Mikel Burguera Arregi. Escuela Técnica Superior de Ingeniería de Bilbao.
Conclusión
La simulación por ordenador en ingeniería es una potente herramienta en ingeniería y STAR-CCM+ es la punta de lanza de su aplicación con computación de altas prestacioes (HPC) en la UPV/EHU. STAR-CCM+ tiene un uso bastante estable a lo largo de los años. Desde un punto de vista económico el reparto del gasto de la licencia este año se ha equilibrado. Desde el punto de vista docente está muy extendido y se generan muchos proyectos con el software.
2016ko txostena: Konputazio Zerbituaren erabileraren errekorra
November 8th, 2017
2016 urteko txostena
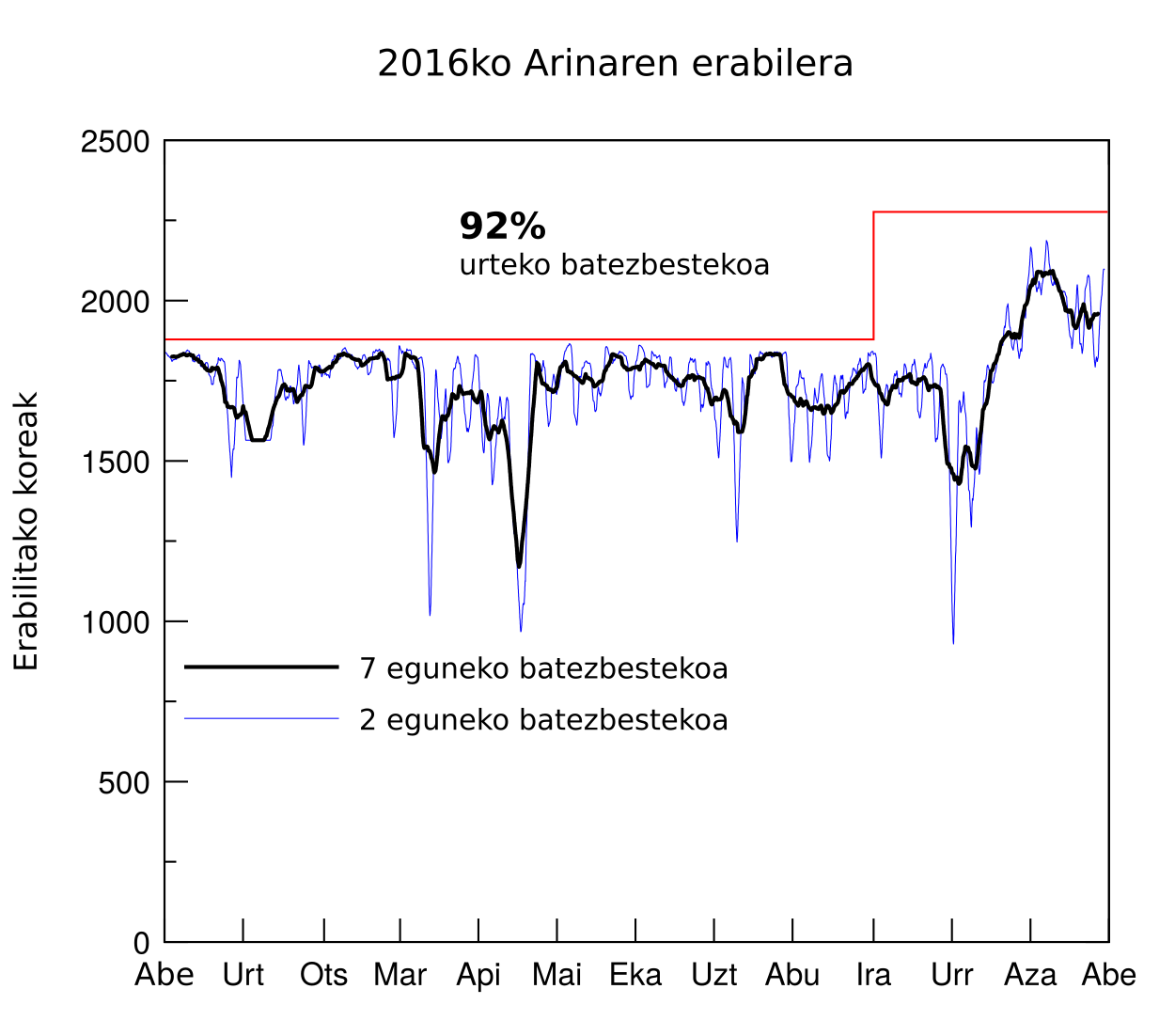
Gure zerbitzuko, Ikerkuntzari Zuzendutako Informatikako Zerbitzu Orokorrako (Kalkulu Zientifikoa), baliabideen erabilera % 92 koa izan da 2016.eko urtea amaieran. Erabilera honek makinen eta inbertsioen aprobetxamendu ezin hobea adierazten du. Hala ere kolan itxarote denbora apur bat igo da. 2016,aren bukaeran eta 2017.aren hasieran instalatutako makina berriei esker, itxarote denbora hauek 2017.-an txikitzea espero dugu. Beste aldetik ere aipagarria da zerbitzua erabiliz lortutako argitalpen kopuruaren igoera.
Artikulu honen bukaerako taulan zerbitzuaren datu aipagarrienak erakusten dira. Datu osoak Zerbitzuko txostenean topa daitezke ondorengo estekan:
Eskeronak
Zerbitzuko memoriarekin batera, zerbitzuko ikertzaileak eskertzen ditugu Zerbitzuan jarritako konfiantzagatik, izan ere, Zerbitzuaren zenbaki onak beraien merituak baitira.
IZO-SGI zerbitzua zenbakietan
Ondorengo taulan azken urteko Zerbitzuko datu esanguratsuenak laburbiltzen dira. Goiko irudian berriz Arinaren erabilera erakusten da.
| 2012 | 2013 | 2014 | 2015 | 2016 | |
| Kalkulu koreak | 1.520 | 1.4 | 1.300¹ | 1.852 | 2.272² |
| Erabilitako kalkulu orduak (milioiak) | 11,3 | 10,4 | 10,1 | 14,0 | 15,2 |
| Investigadores activos | 89 | 99 | 107 | 104 | 116 |
| Talde aktiboak | 40 | 47 | 45 | 42 | 38 |
| Kontu berriak | 20 | 34 | 23 | 43 | 43 |
| Ikertzaileen satisfakzioa¹ | 9,3 | 9,3 | 9,6 | 9,5 | 9.5 |
| Artikulu zientifikoak² | 74 | 87 | 75 | 85 | 94 |
| Web bisitak | 9.899 | 5.924 | 2.34 | 2.902 | 5.152 |
| Orrialde ikusiak | 30.738 | 20.323 | 12.057 | 10.799 | 12.887 |
| Postak HPC blogan | 27 | 47 | 36 | 30 | 11 |
| Postak HPC blogan | 4.741 | 24.613 | 23.677 | 20.67 | 18.554 |
| Arina | |||||
| Kalkulu koreak | 1.360 | 1.32 | 1.3 | 1.892 | 2.172² |
| Erabilitako kalkulu orduak (milioiak) | 9,6 | 9,8 | 10,1 | 14,0 | 15,2 |
| Okupazio batez bestekoa | 79 % | 83 % | 87 % | 86 % | 92 % |
| Bidalitako lanak | 98.383 | 100.214 | 76.912 | 115.681 | 115.172 |
| 2 minutuko baino gehiagoko lanak⁴ | 78.846 | 75.406 | 64.335 | 100.131 | 98.472 |
| Batez besteko lanen denbora (ordutan)⁵ | 122 | 130 | 156 | 140 | 132 |
| Batez besteko itxaron denbora (ordutan)⁶ | 5,2 | 5,5 | 10,0 | 14 | 15,1 |
| Péndulo | |||||
| Kalkulu koreak | 80 | 80 | 70 | — | — |
| Erabilitako kalkulu orduak (milioiak) | 0,07 | 0,04 | 6 | — | — |
| Ikerbasque⁸ | |||||
| Kalkulu koreak | 208 | 208 | — | — | — |
| Erabilitako kalkulu orduak (milioiak) | 1,6 | 0,55 | — | — | — |
¹ 2014 bukaerako makina berriekin 1850 koretara.
² 2016 Irailean 420 kore gehitu ziren.
³ SGIker Kalitate unitateagatik egindako zerbitzuari buruzko inkesta.
⁴ Non IZO-SGI eskertzen da.
⁵ 2 minutu baino gutxiago irauten duten lanak normalean kale egin duten lanak dira. Bere iraupen motxagatik pisu txikia dute clusterraren erabileran.
⁶ Ez dira kontutan hartu bi minutu baino gutxiagoko lanak.
⁷ Lanek kola sistema baten bitartez bideratzen dira zeinek lan bakoitzari dagokion baliabideak ematen dizkio. Lanen itxaron denbora kolan baliabideak itxoiten ematen duten denbora da.
⁸ Makina 2013ko apirilean itzali zen.
2016 report: Scientific Computing Service occupancy record
November 8th, 2017
2016 Report
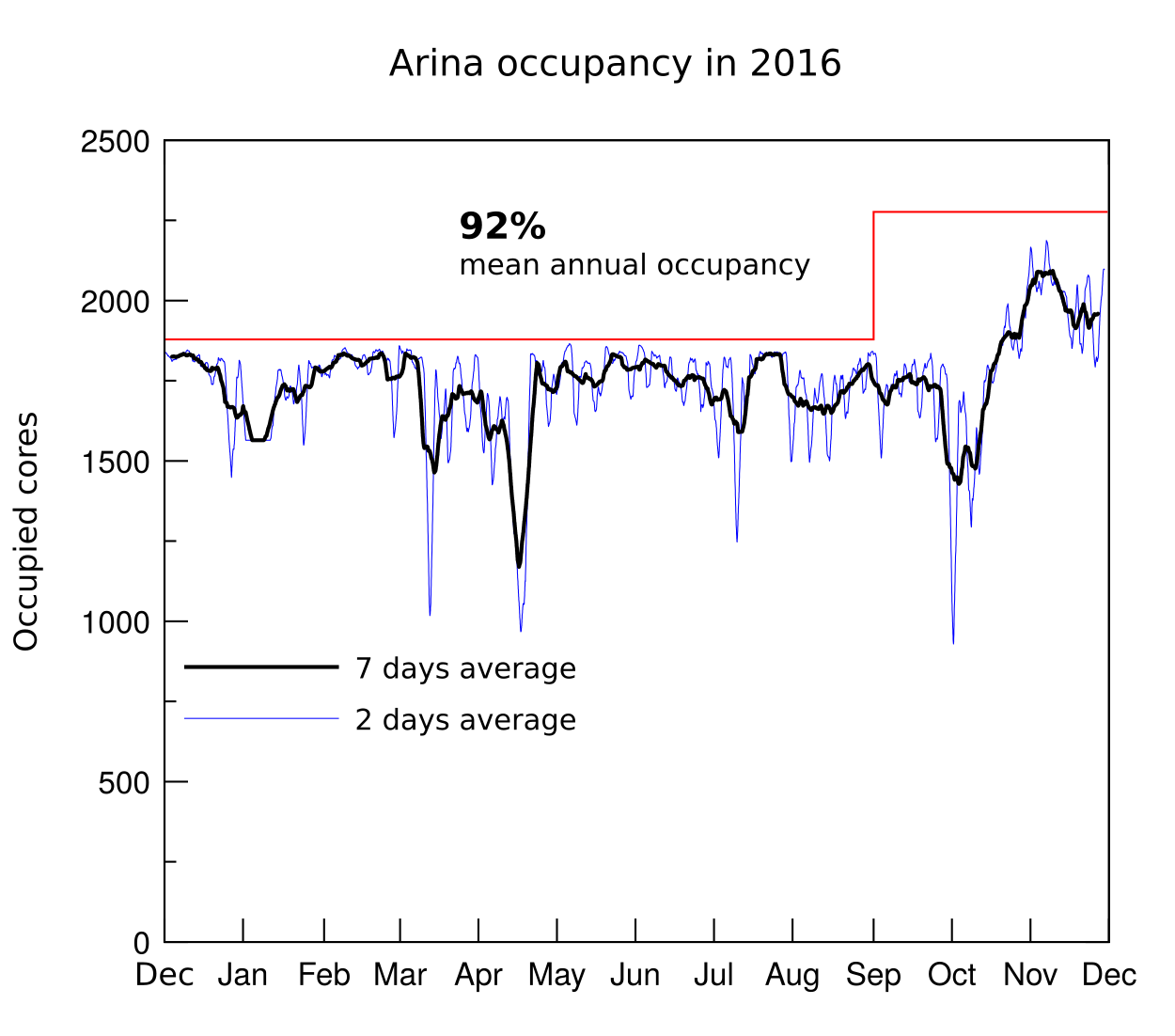
We close 2016 with an occupancy record of 92% in the Arina cluster of the IZO-SGI Scientific Computing Service. This occupation shows an excellent usage of the resources and inversions. The counterpart has been a slight increase in queue time, although we hope that this will be reduced in 2017 after the two increases in computing resources installed at the end of 2016 and mid-2017. On the other hand, it is also worth highlighting the increase in the number of publications which thanks to the Service.
The table at the end of this article contains the most relevant figures for the Service. Full details can be found in the Service’s memory at the following link (in spanish):
2016 Scientific Computing Service report (pdf)
Aknowledgements
We would like to thank the researchers for their trust in the Service, since the good numbers of the Service have been their achievements.
The Scientific Computing Service in figures
The following table summarizes the most significant data of the Scientific Computing Service in the last years.
| 2012 | 2013 | 2014 | 2015 | 2016 | |
| Computing cores | 1.520 | 1.4 | 1.300¹ | 1.852 | 2.272² |
| Used millions of computing hours | 11,3 | 10,4 | 10,1 | 14,0 | 15,2 |
| Active researchers | 89 | 99 | 107 | 104 | 116 |
| Activos groups | 40 | 47 | 45 | 42 | 38 |
| New accounts | 20 | 34 | 23 | 43 | 43 |
| Researcher’s satisfaction³ | 9,3 | 9,3 | 9,6 | 9,5 | 9.5 |
| Scientific articles⁴ | 74 | 87 | 75 | 85 | 94 |
| Web visits | 9.899 | 5.924 | 2.34 | 2.902 | 5.152 |
| Page views | 30.738 | 20.323 | 12.057 | 10.799 | 12.887 |
| Posts in the HPC blog | 27 | 47 | 36 | 30 | 11 |
| Page views of the HPC blog | 4.741 | 24.613 | 23.677 | 20.67 | 18.554 |
| Arina | |||||
| Computing cores | 1.360 | 1.32 | 1.3 | 1.892 | 2.172² |
| Used millions of computing hours | 9,6 | 9,8 | 10,1 | 14,0 | 15,2 |
| Average occupation | 79 % | 83 % | 87 % | 86 % | 92 % |
| Sent jobs | 98.383 | 100.214 | 76.912 | 115.681 | 115.172 |
| Jobs larger than 2 minutos⁵ | 78.846 | 75.406 | 64.335 | 100.131 | 98.472 |
| Average hours per job⁶ | 122 | 130 | 156 | 140 | 132 |
| Waiting time per job ⁷ | 5,2 | 5,5 | 10,0 | 14 | 15,1 |
| Péndulo | |||||
| Computing cores | 80 | 80 | 70 | — | — |
| Used millions of computing hours | 0,07 | 0,04 | 6 | — | — |
| Ikerbasque⁸ | |||||
| Computing cores | 208 | 208 | — | — | — |
| Used millions of computing hours | 1,6 | 0,55 | — | — | — |
¹ At the end of 2014 the numbers of cores increased up to 1850.
² In September the number of cores increased up to 2016.
³ Service User Satisfaction Survey.
⁴ With thanks to IZO-SGI.
⁵ Jobs of less than 2 minutes are usually due to unsuccessful runs that end immediately with an error. In any case, even if this is not the case, given their short duration, they do not affect the cluster.
⁶ Jobs of less than two minutes has not been taken into account.
⁷ Jobs are executed through a queue system that assigns to each job the resources that have been requested and orders its execution to optimize the use of the cluster. Queue time is the time that jobs are waiting until the resources they need are released.
⁸ The machine was shut down in April 2013.
Memoria del 2016: Ocupación record del Servicio de Computación
October 24th, 2017
Memoria 2016
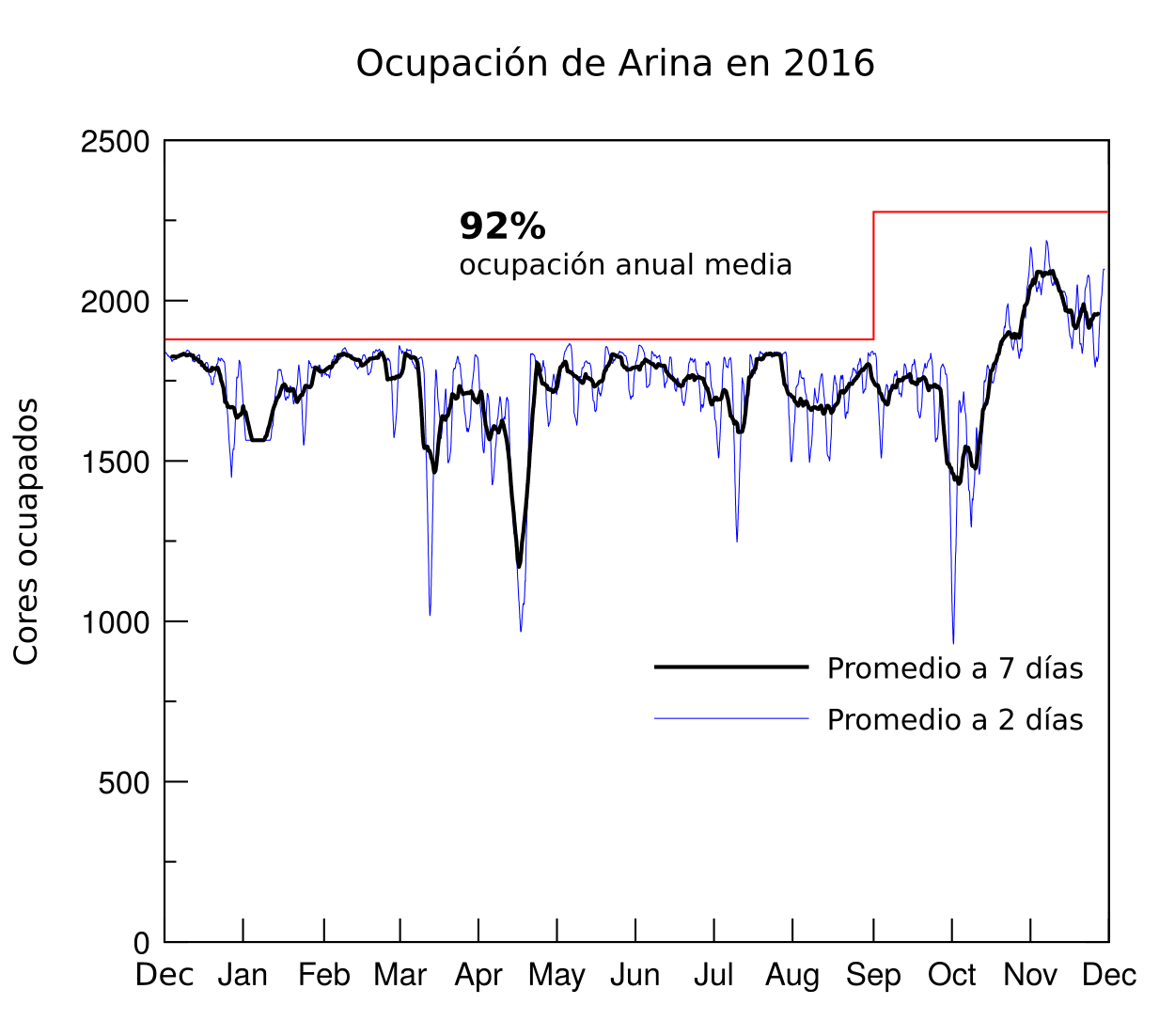
Cerramos el 2016 con una ocupación record del 92% en el cluster de Cálculo Arina en el El Servicio de Informática Aplicada a la Investigación (Cálculo Científico) IZO-SGI SGIker. Esta ocupación supone un excelente aprovechamiento de las inversiones realizadas. La contrapartida ha sido un ligero aumento del tiempo de espera en cola, aunque esperemos este se reduzca en 2017 gracias a los dos incrementos de recursos computacionales realizados a finales de 2016 y mediados de 2017. Por otro lado también es de destacar el incremento en el número de publicaciones con agradecimientos al Servicio.
En la tabla al final de este artículo están las cifras más relevantes del Servicio. Los datos completos pueden encontrarse en la memoria del Servicio en el siguiente enlace:
IZO-SGI memoria del 2016 (pdf)
Agradecimientos
Queremos aprovechar estas líneas para agradecer la confianza depositada en el Servicio por los investigadores dado que buena parte de los buenos números del Servicio son más mérito suyo que nuestro.
El IZO-SGI en cifras
En la siguiente tabla se resumen los datos más significativos del Servicio de cálculo en los últimos años.
| 2012 | 2013 | 2014 | 2015 | 2016 | |
| Cores de cálculo | 1.520 | 1.4 | 1.300¹ | 1.852 | 2.272² |
| Millones de horas de cálculo consumidas | 11,3 | 10,4 | 10,1 | 14,0 | 15,2 |
| Investigadores activos | 89 | 99 | 107 | 104 | 116 |
| Grupos activos | 40 | 47 | 45 | 42 | 38 |
| Cuentas nuevas | 20 | 34 | 23 | 43 | 43 |
| Satisfacción de los investigadores³ | 9,3 | 9,3 | 9,6 | 9,5 | 9.5 |
| Artículos científicos⁴ | 74 | 87 | 75 | 85 | 94 |
| Visitas web | 9.899 | 5.924 | 2.34 | 2.902 | 5.152 |
| Páginas vistas | 30.738 | 20.323 | 12.057 | 10.799 | 12.887 |
| Posts en el blog HPC | 27 | 47 | 36 | 30 | 11 |
| Visitas del blog HPC | 4.741 | 24.613 | 23.677 | 20.67 | 18.554 |
| Arina | |||||
| Cores de cálculo | 1.360 | 1.32 | 1.3 | 1.892 | 2.172² |
| Millones de horas consumidas | 9,6 | 9,8 | 10,1 | 14,0 | 15,2 |
| Promedio de ocupación | 79 % | 83 % | 87 % | 86 % | 92 % |
| Trabajos enviados | 98.383 | 100.214 | 76.912 | 115.681 | 115.172 |
| Trabajos de más de 2 minutos⁵ | 78.846 | 75.406 | 64.335 | 100.131 | 98.472 |
| Horas promedio por trabajo⁶ | 122 | 130 | 156 | 140 | 132 |
| Horas promedio de espera ⁷ | 5,2 | 5,5 | 10,0 | 14 | 15,1 |
| Péndulo | |||||
| Cores de cálculo | 80 | 80 | 70 | — | — |
| Millones de horas consumidas | 0,07 | 0,04 | 6 | — | — |
| Ikerbasque⁸ | |||||
| Cores de cálculo | 208 | 208 | — | — | — |
| Millones de horas consumidas | 1,6 | 0,55 | — | — | — |
¹ A finales de 2014 con la ampliación se llegó a los 1850 cores.
² Ampliación en Septiembre de 2016 de 420 cores.
³ Encuesta de satisfacción de los usuarios del Servicio realizada por la Unidad de Calidad de SGIker.
⁴En los que se agradece al IZO-SGI.
⁵ Los trabajos de menos de 2 minutos se deben normalmente a trabajos fallidos que terminan inmediatamente en error. En cualquier caso, aun de no ser así, dada su corta duración no repercuten en el cluster.
⁶ No se han tenido en cuenta los trabajos de menos de dos minutos.
⁷ Los trabajos se ejecutan a través de un sistema de colas que asigna a cada trabajo los recursos que se le han solicitado y ordena su ejecución para optimizar el uso del cluster. El tiempo en cola es el tiempo que están esperando los trabajos hasta que se liberan los recursos que necesitan.
⁸ La máquina se apagó en Abril de 20133.
Resultados de la encuesta de satisfacción 2016 del Servicio
October 23rd, 2017
Publicamos los resultados de la encuesta de satisfacción del personal investigador del Servicio de Cálculo Científico. 63 investigadoras e investigadores respondieron la encuesta de los 116 que nos usaron en 2016.
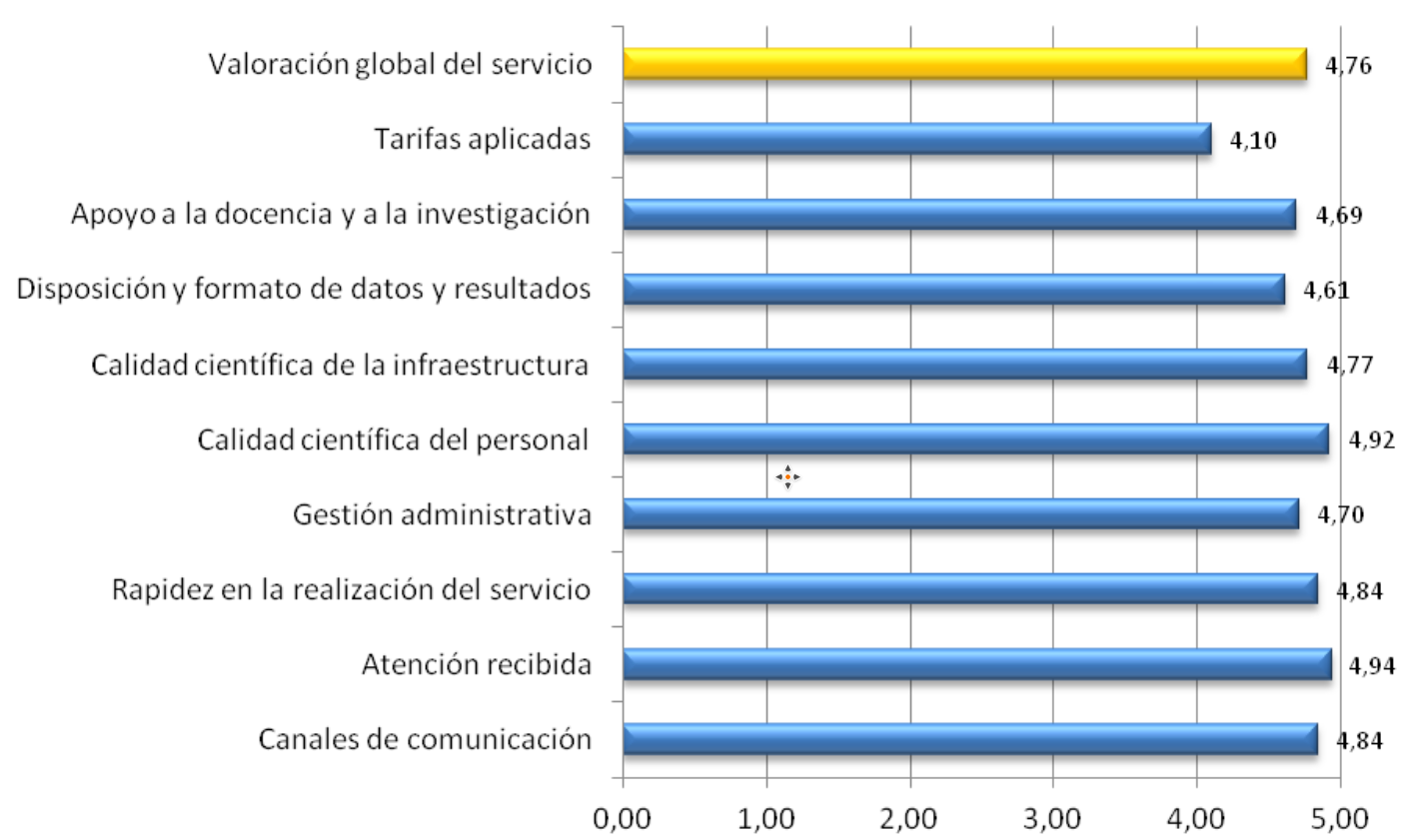
En cuanto a la valoración global del Servicio, que es una de las preguntas de la encuesta y no una media, en 2016 obtenemos una valoración de 4.76, en línea con años anteriores como se puede observar en la gráfica y por encima de la media global de los Servicios Generales de Investigación (SGIker). La escala es de 0 a 5.

En cuanto al análisis detallado de los diferentes apartados podemos destacar como los elementos mejor valorados la atención recibida y la calidad científica del personal. Al igual que en años anteriores las tarifas aplicadas son el elemento peor valorado, que si bien no está mal valorado en términos absolutos, si en términos relativos si se compara con el resto de elementos.
A continuación mostramos los comentarios enviados que reflejan la misma percepción del Servicio que los resultados cuantitativos.
- The staff was always very helpful when a problem occurred.
- Hay dos personas de soporte técnico controlando el ordenador Arina, casualmente una de ellas ha debido de solicitar una excedencia. Por consiguiente,
una sola persona dando soporte a todos los usuarios es insuficiente. Deberı́a de existir más personal de soporte para poder hacer frente a la demanda. Y si alguien cae enfermo o tiene que estar fuera por el motivo que sea, que no se note tanto la falta de personal. - Estos dı́as, desde SGIker, se está cuestionando la continuidad del software ”STAR-CCM+”, atendiendo criterios de rentabilidad económica. Creo personalmente que posibilitar el uso de este software supone un alto valor añadido para la docencia de diferentes asignaturas en nuestro área de conocimiento, Mecánica de Fluidos, y posibilita también grandes posibilidades de desarrollo en I+D+i para el mismo área. Si el servicio va ligado al uso de sistema de colas en ARINA (que se nos comenta está infrautilizado), creo que se deberı́a haber dejado claro de partida. Dado que algunos profesores (no es mi caso) han optado por la compra de estaciones de trabajo potentes, restando importancia a la supercomputación en ARINA. En mi caso, uso ARINA cuando lo necesito y siempre me ha parecido la opción más atractiva técnicamente, y rentable económicamente. Por otro lado, para simulación de casos menores, con el PC es suficiente (cada vez los PC dan mayor cobertura en el análisis de casos cada vez más complejos: número de celdas del, mallado, adición de modelos fı́sicos, etc). El servicio que dan los profesionales es excepcional, respondiendo y resolviendo problemas de forma adecuada en plazos muy cortos de tiempo. Esperando que tengan en consideración estos comentarios. Un cordial saludo.
- Sakondu orain arte hartutako norabidean.
- The facility is sometimes busy and more nodes will be welcomed.
- Services are very expensive.
- El precio del tiempo de cálculo es excesivo.
- Los precios son algo elevados para un usuario habitual.
2016.-eko Zerbitzuari buruzko inkestaren emaitzak
October 23rd, 2017
2016. Urteko Zerbitzuari buruzko gogobetetze inkestaren emaitzak argitaratu ditugu. 63 ikertzaileek osatu dute inkesta, gure baliabideak erabiltzen 116 ikertzaile izan genituen bitartean.
Galdetutako Zerbitzuaren buruzko balorazio orokorra aztertuz, 4.76 puntutakoa izan da (0tik 5era neurtuta). Grafikan ikus daitekenez azken urteotan izandako balorazioaren parekoa, eta Ikerkuntzako Zerbitzu Orokorretatako (SGIker) bataz besteko orokorra baino handiagoa.
Azterketa sakonagoa eginda gero, eskeinitako arreta eta teknikarien kalitate zientifikoa nabarmendu daitezke. Bestalde, urtero bezala, tarifa izan da okerren baloratua. Berez, balorazioa txarra ez bada ere, bai ordea beste atalen balorazioarekin aldaratzen badugu.
Bukatzeko, erabiltzaileek egindako oharrak erakusten ditugu inkestaren azterketa orokorrarekin bat datozenak.
- The staff was always very helpful when a problem occurred.
- Hay dos personas de soporte técnico controlando el ordenador Arina, casualmente una de ellas ha debido de solicitar una excedencia. Por consiguiente,
una sola persona dando soporte a todos los usuarios es insuficiente. Deberı́a de existir más personal de soporte para poder hacer frente a la demanda. Y si alguien cae enfermo o tiene que estar fuera por el motivo que sea, que no se note tanto la falta de personal. - Estos dı́as, desde SGIker, se está cuestionando la continuidad del software ”STAR-CCM+”, atendiendo criterios de rentabilidad económica. Creo personalmente que posibilitar el uso de este software supone un alto valor añadido para la docencia de diferentes asignaturas en nuestro área de conocimiento, Mecánica de Fluidos, y posibilita también grandes posibilidades de desarrollo en I+D+i para el mismo área. Si el servicio va ligado al uso de sistema de colas en ARINA (que se nos comenta está infrautilizado), creo que se deberı́a haber dejado claro de partida. Dado que algunos profesores (no es mi caso) han optado por la compra de estaciones de trabajo potentes, restando importancia a la supercomputación en ARINA. En mi caso, uso ARINA cuando lo necesito y siempre me ha parecido la opción más atractiva técnicamente, y rentable económicamente. Por otro lado, para simulación de casos menores, con el PC es suficiente (cada vez los PC dan mayor cobertura en el análisis de casos cada vez más complejos: número de celdas del, mallado, adición de modelos fı́sicos, etc). El servicio que dan los profesionales es excepcional, respondiendo y resolviendo problemas de forma adecuada en plazos muy cortos de tiempo. Esperando que tengan en consideración estos comentarios. Un cordial saludo.
- Sakondu orain arte hartutako norabidean.
- The facility is sometimes busy and more nodes will be welcomed.
- Services are very expensive.
- El precio del tiempo de cálculo es excesivo.
- Los precios son algo elevados para un usuario habitual.
Results of the Computing Service’s 2016 satisfaction survey
October 23rd, 2017
We publish the 2016 Scientific Calculation Service satisfaction survey results. We had 113 researchers that used our resources in 2016 and 63 answers to the survey.
The general evaluation of the Service, which is one of the survey questions and not an average, is 4.76 points, in line with previous years and above the overall average of the General Research Services (SGIker) of our university as can be seen in the graph.
In a detailed analysis of the different sections, we can highlight the attention received and the scientific quality of the staff as the best rated elements. As in previous years, applied rates is the worst rated one, which is not badly rated in absolute terms, but in relative terms when compared to the rest of the elements it scores poorly.
Finall we show the comments that the users wrote, that reflect the same perception as the quantitative results of the Service .
- The staff was always very helpful when a problem occurred.
- Hay dos personas de soporte técnico controlando el ordenador Arina, casualmente una de ellas ha debido de solicitar una excedencia. Por consiguiente,
una sola persona dando soporte a todos los usuarios es insuficiente. Deberı́a de existir más personal de soporte para poder hacer frente a la demanda. Y si alguien cae enfermo o tiene que estar fuera por el motivo que sea, que no se note tanto la falta de personal. - Estos dı́as, desde SGIker, se está cuestionando la continuidad del software ”STAR-CCM+”, atendiendo criterios de rentabilidad económica. Creo personalmente que posibilitar el uso de este software supone un alto valor añadido para la docencia de diferentes asignaturas en nuestro área de conocimiento, Mecánica de Fluidos, y posibilita también grandes posibilidades de desarrollo en I+D+i para el mismo área. Si el servicio va ligado al uso de sistema de colas en ARINA (que se nos comenta está infrautilizado), creo que se deberı́a haber dejado claro de partida. Dado que algunos profesores (no es mi caso) han optado por la compra de estaciones de trabajo potentes, restando importancia a la supercomputación en ARINA. En mi caso, uso ARINA cuando lo necesito y siempre me ha parecido la opción más atractiva técnicamente, y rentable económicamente. Por otro lado, para simulación de casos menores, con el PC es suficiente (cada vez los PC dan mayor cobertura en el análisis de casos cada vez más complejos: número de celdas del, mallado, adición de modelos fı́sicos, etc). El servicio que dan los profesionales es excepcional, respondiendo y resolviendo problemas de forma adecuada en plazos muy cortos de tiempo. Esperando que tengan en consideración estos comentarios. Un cordial saludo.
- Sakondu orain arte hartutako norabidean.
- The facility is sometimes busy and more nodes will be welcomed.
- Services are very expensive.
- El precio del tiempo de cálculo es excesivo.
- Los precios son algo elevados para un usuario habitual.
 HPC @UPV/EHU
HPC @UPV/EHU
- Special Issue “Large Eddy Simulation and Turbulence Modeling”
- Licencias de software Siemens PLM
- Solicitud 2018 de licencias de STAR-CCM+ y HEEDS para investigación y docencia
- Memoria sobre el uso de STAR-CCM+ en 2017
- 2016ko txostena: Konputazio Zerbituaren erabileraren errekorra
- 2016 report: Scientific Computing Service occupancy record

Comentarios