In the Scientific Computing Service of the UPV/EHU (IZO-SGI) we believe that we can strongly support scientific funding applications for research projects involving High Performance Computing (HPC) due to our service quality and reputation gained over the last 10 years. European computing resources access policy boosts the access to shared computing resources as the ones of the IZO-SGI, in opposition to resources monopolized by individual users or groups.
From this point of view, we have prepared this detailed technical and management report regarding our Service that you might find interesting to include in your funding applications to access High Performance Computing infrastructure. For any questions, requests or clarifications do not hesitate to contact us.
Feel free to copy, summarize or adapt this text to your requirements.
Introduction
The Scientific Computing Service (IZO-SGI) belongs to the UPV/EHU General Research Services (SGIker). The Service provides access to outstanding High Performance Computing (HPC) resources, software and support. It gives service to the entire scientific community of the Basque Country, including researchers from the UPV/EHU (main research institution in the Basque Country), but also to the entire scientific and industrial community. The Service holds, since 2004, an HPC cluster that has regularly been expanded to meet the growing demand of HPC resources by the wide variety of research groups covering all areas of Science (Physics, Chemistry, Engineering, Computer Science, Mathematics, Biology, Geology, Economics, etc).
Infraestructure
An HPC cluster is not standard IT equipment, it is a complex scientific equipment assembled with very specific elements. As that, it requires highly qualified personnel and should be placed in a space designed to guarantee its optimal performance. The HPC cluster of the IZO-SGI has been designed internally to satisfy the needs of a broad spectrum of researchers as a single heterogeneous computing entity. This heterogeneity makes it a flexible and valuable tool nearly for all areas of science, as demonstrated by the wide range of researchers who used it. The resources are summarized below:
- Bianual resources update policy.
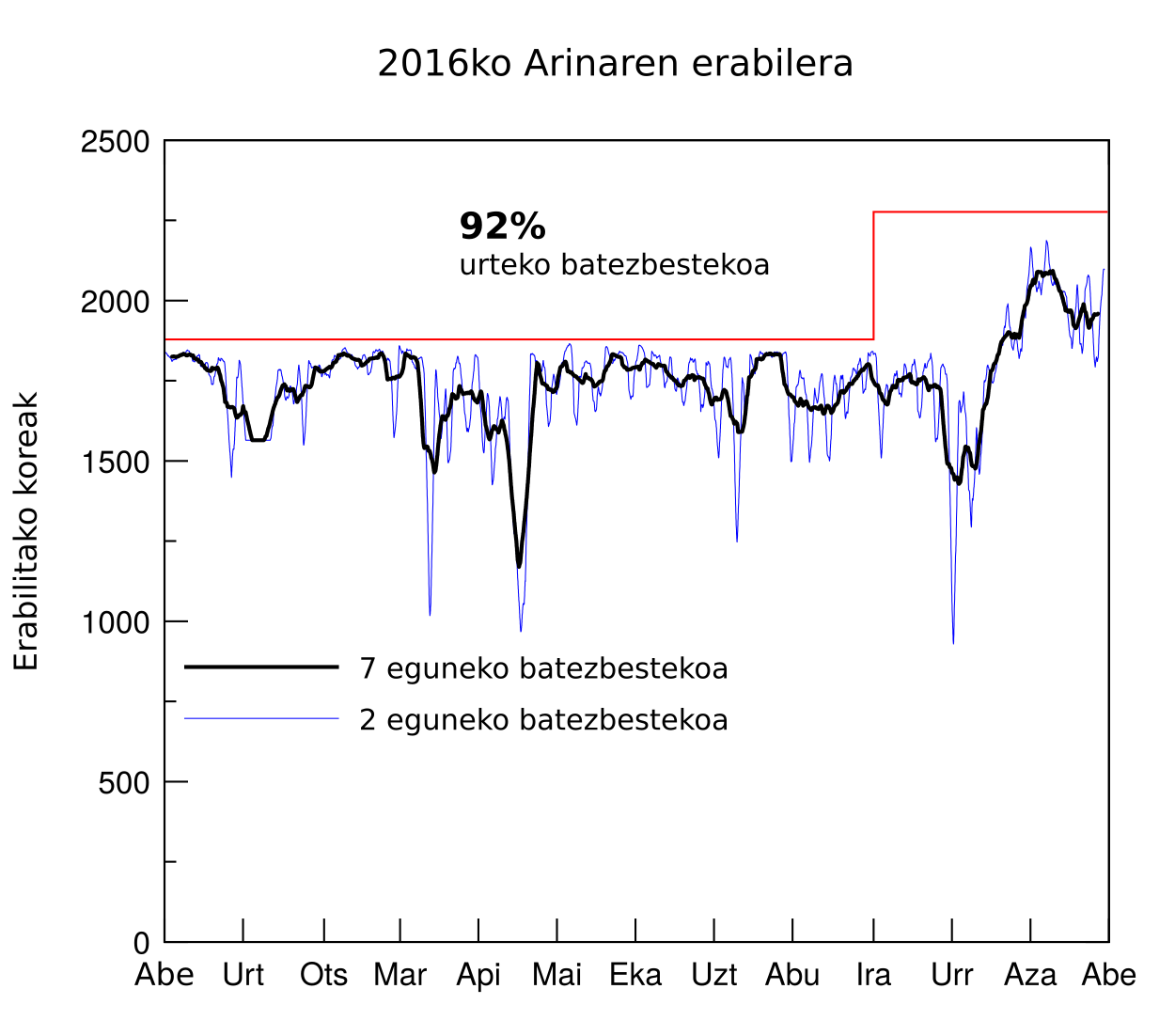
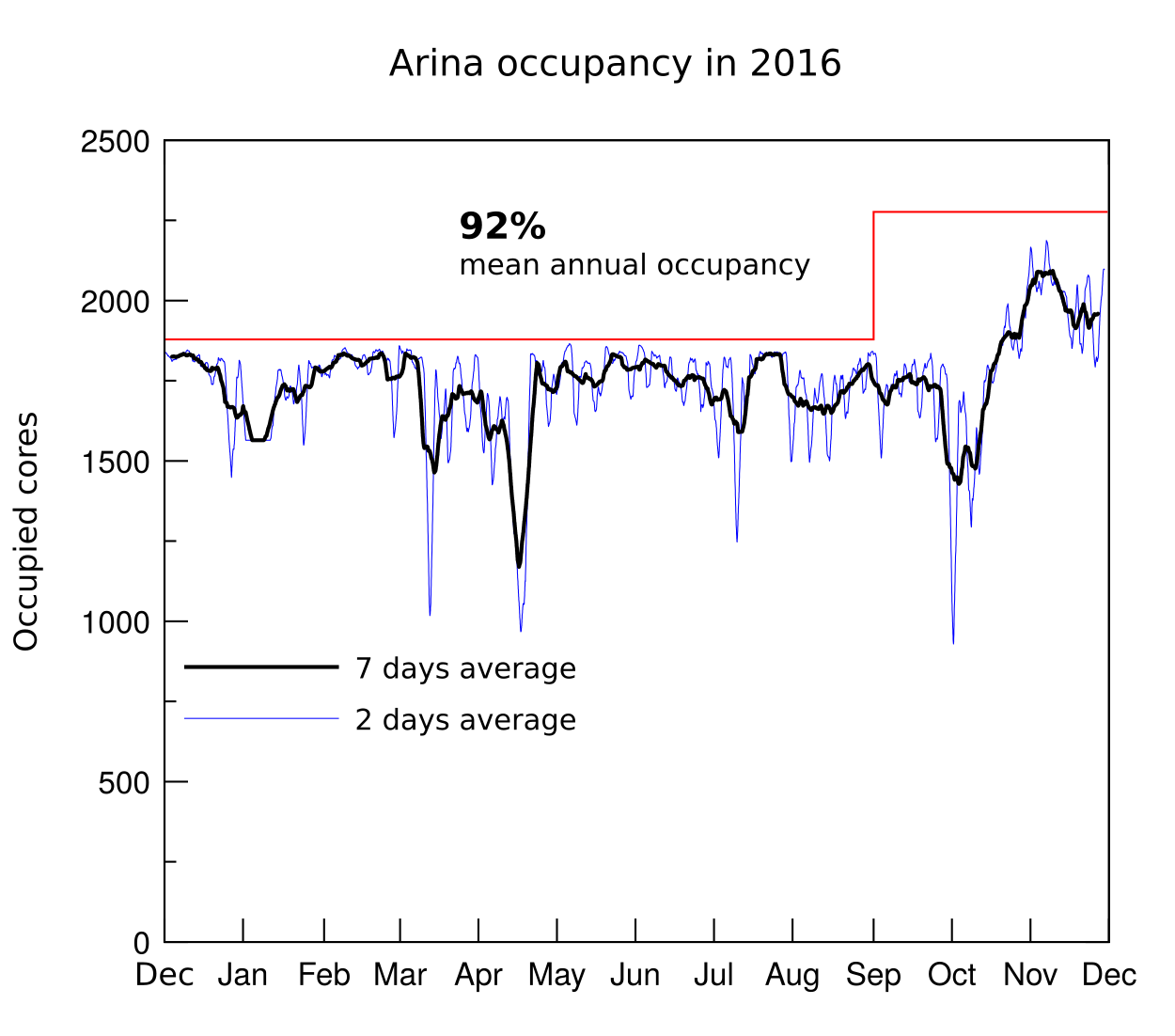
- 3728 computational cores with IA64 and x86-64 architectures that allow the execution of standard and massive calculations..
- 6 Nodes with 2 Nvidia GPGPUs each to exploit the programs that use this new technology.
- Nodes with large RAM for jobs with these specific requirements (up to 512 GB of RAM).
- High performance, high capacity and high read/write speed filesystems based on Lustre. 3 different systems with up to 40 TB of storage and 7 GB/s read and write speed.
- Everything interconnected with a high bandwidth and low latency InfiniBand network. The last acquisition with 56 Gb/s Infiniband FDR.
- Management servers under high availability to ensure 24h*365 operation.
- Everything installed in the Data Processing Center (DPC) of the UPV/EHU with a all the elements to ensure optimal performance of the cluster (see next point for details of the DPC).
For a more detailed technical specification visit the computational resources web page of the Service.
The concentration of human and computational resources in the IZO-SGI makes a community and provides to research groups access to a qualitatively and quantitatively superior resources, which result in an increasing scientific productivity. Analogously, the use and amortization of the infrastructure and related secondary costs is extremely efficient and effective.
Data processing Center
The equipment is installed in the DPC of the UPV/EHU newly built in 2006. The DPC has 450 m² and is intended to guarantee the proper and continuous functioning of the computers hosted therein. For that, it is fully equipped with elements that makes possible the 24x7x365 functioning of the cluster:
- Precision air conditioning systems exclusive and direct expansion water softening system. 7 air conditioning units with an aggregate capacity of 208KW, ensuring N+1 redundancy against failure.
- Fire system. Fire detection system using optical and thermal detectors. HI-FOG water mist extinguishing system that preserves the integrity of computer equipment in case of activation.
- Connection to two separate electrical power transformers.
- Double electric branch for IT equipment, each with independent UPS (uninterruptible power supplies) and separate low voltage boxes. It allows redundancy and maintenance without power off of the electrical installation.
- 750 KVA power generator with two days of autonomy without refueling.
- Access control, alarms and security by closed circuit TV.
- User and systems data backup.
- Monitoring, management and control by in-situ operators.
- 5S method to improve the quality.
The facilities are monitored in-situ and remotely with maintenance and periodic revisions in order.The ICT department has a secondary DPC in another building, that keeps duplicate the basic services to prevent operation failures in an event of a major disaster. For example, backups are performed on this DPC to maintain separate data and backups.
Other services
The ICT department maintains the UPV/EHU data network that consists of front-line and last generation technologies. This allows to establish connections with high bandwidth (up to 10Gbps) and a high degree of security, which is essential to work effectively in an infrastructure where all the researches connect remotely. The network has redundant hardware elements and communication lines with diversified duplicate paths and a perimeter firewall, network demilitarized zones, balancers, hardware detection systems of unsafe or potentially dangerous sources, etc. The Internet external connection is done through i2basque, the regional scientific network, which in turn connects to RedIRIS, the Spanish academic and research network.
The ICT department also offers a massive storage system for researchers which is integrable in the IZO-SGI. This storage service is highly secure, there is a mirror in the secondary CPD, and is scalable in capacity and bandwidth to meet current and future requirements.
Personnel
Specific techncal staff
An HPC cluster is a very complex scientific equipment. The specific, particular design and management that requires the IZO-SGI cluster is carried out by two doctors with extensive experience in Scientific Computing. They manage the Service since 2004 and previous experience in HPC obtained during their doctoral formation. Specifically, the two technicians have academic background (PhD) in Chemistry and Physics, two of the scientific areas that make heavier use of HPC, allowing them to offer a service of scientific advice with high added value.
The administrative structure of the SGIker, 12 people, is responsible for administrative tasks such as financial management, management and general administration. Other SGIker units give also internal support such as Quality Service and Innovation, Science metrics and infrastructure.
Non specific personnel
A scientific director with extensive experience, knowledge and vision of HPC in general and in the field of computational chemistry in particular guides the service in making strategic decisions.
The ICT deparment is the largest department of the UPV/EHU in personnel. The staff dedicated to computing tasks far exceeds 150 people. Calculation Service IZO-SGI maintains close contact and cooperation with various areas:
- With the operation area that provides maintenance services, equipment, monitoring, etc. that the IZO-SGI uses.
- With the network area to enable network services, ports, rules, etc. that are required for the proper functioning of hardware and software and allow remote connection of researchers to our clusters.
- With the teaching support area supports us in managing the Pendulum GRID that uses teaching computer rooms for computing at nights. Also for the installation of software that manages the IZO-SGI that is used for teaching in addition to research.
- With the area of customer service, which solves problems in the searchers PCs. They support and solved on-site more efficiently problems such as installing software on their personal computers.
The integration of the IZO-SGI into the UPV/EHU provides also all the administrative and technical services of the UPV/EHU structure.
Quality and evaluation policy
SGIker is committed with the quality and have defined quality policy that serves as a frame of reference in setting goals, targets and implement quality programs. The quality of services offered is the cornerstone of the SGIker. Proof of this commitment is the existence of Quality and Innovation Unit that focuses its efforts on the implementation, maintenance and continuous improvement of a System of Quality Management based on international standards.
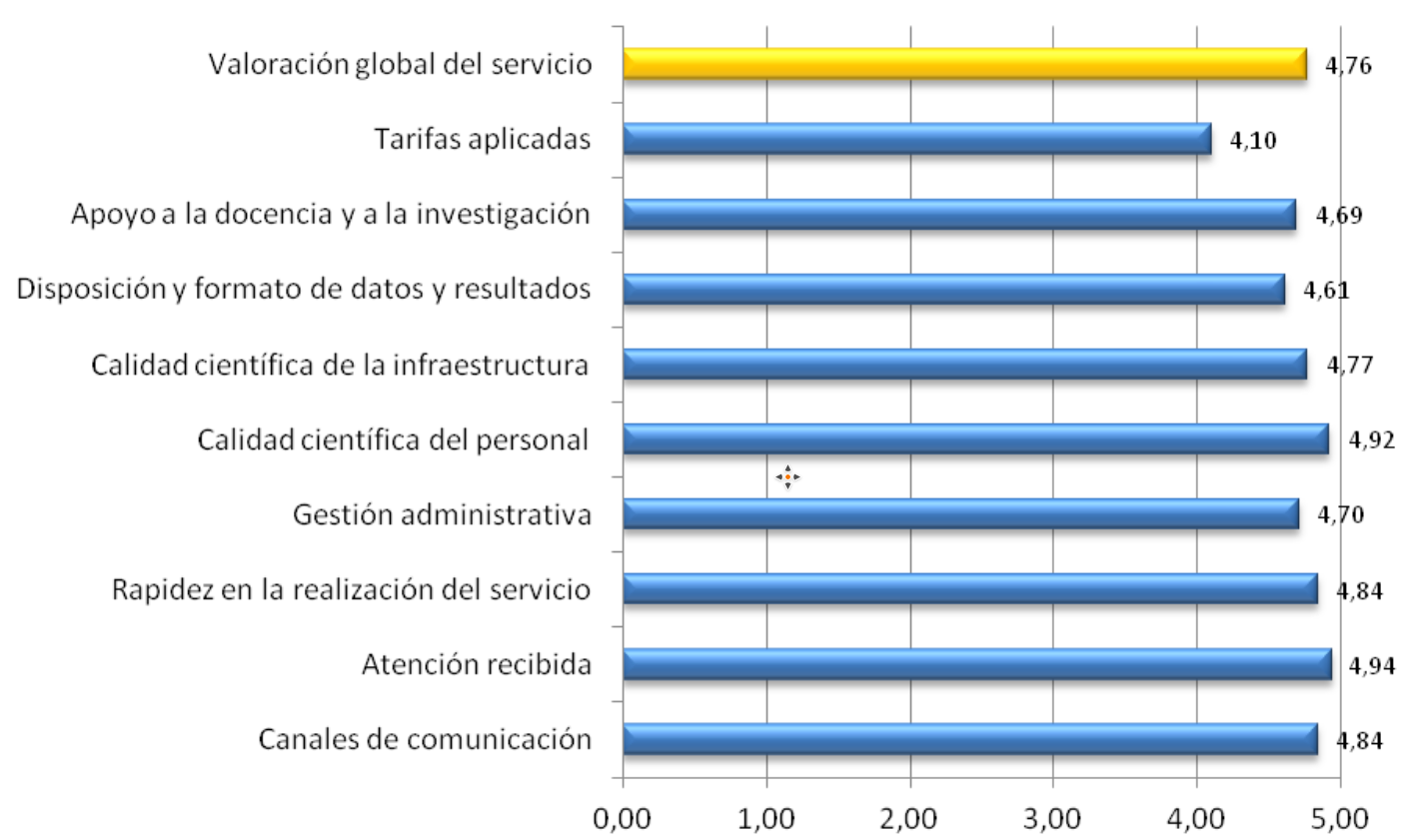
The Quality and Innovation Unit of the General Research Services SGIker carries out, every year, among researchers an user satisfaction independent survey. The IZO-SGI has an 9.6 average over the last five years.
General, IZO-SGI




Comentarios